Speculative Decoding
What if instead of generating one token at a time in Decode, we could generate multiple? This is the premise of Speculative Decoding.
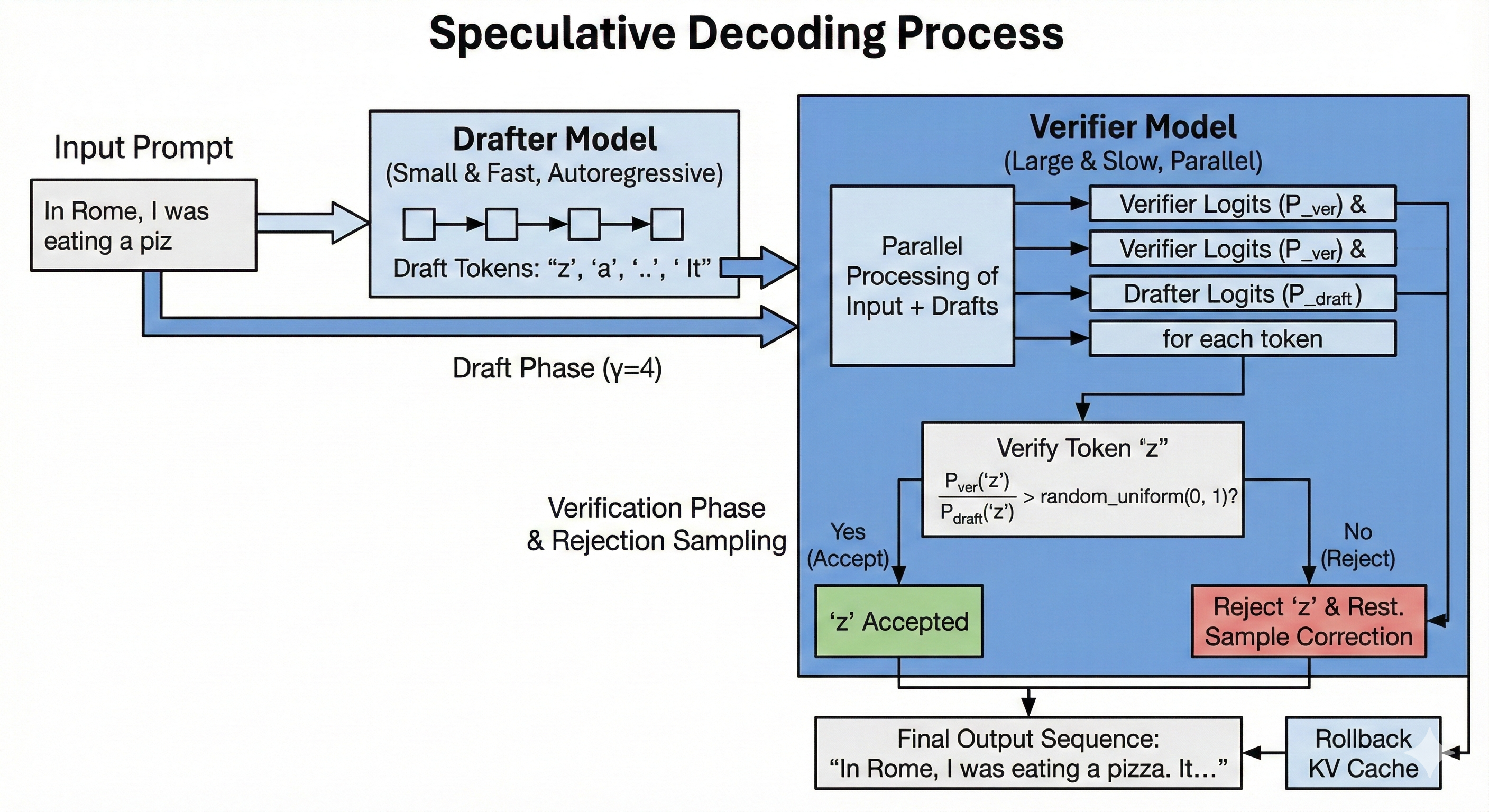
This paper observes that most tokens are relatively easy to predict. For instance the sentence, In Rome, I was eating a piz, the next token is very easy to predict as za. We do not need a massive model to predict it. So instead, let's use a smaller, less capable, but much faster model to predict easy tokens and have the large model intervene for the harder ones.
How it works
We call the small model the Drafter and the large model the Verifier.
We first have to pick an existing small model, or train a Drafter to aproximate the distribution of the Verifier model with a much smaller number of parameters.
Then during inference, before each Verifier step, we first run multiple steps of the Drafter, for instance 4, we call this number \(\gamma\). Then, we add the \(\gamma\) generated tokens to the Verifier's input and we run them through the model in parallel.
At the end, we loop over the distributions of each output token.
- We compare the probability distribution of the
Drafteragainst theVerifier. If the token drawn by theDrafteris plausible enough according to the Verifier, we accept it. - Otherwise, we reject the token and resample it with an adjusted distribution \(p'(x) = norm(max(0, p_{verifier}(x) - p_{drafter}(x)))\). We stop here and reject the rest of the predicted tokens.
- If we accepted all tokens, we use the model's last prediction.
This means that if we set \(\gamma = 4\), each step might generate between 1 and 5 tokens.
Mathematical Intuition
The formula for accepting a token is \[\text{is_accepted} = \text{random_uniform}(0, 1) < \frac{P_{\text{verifier}}(x)}{P_{\text{drafter}}(x)}\]
If the Verifier thinks the token is more likely than the Drafter did, we always accept. If it thinks it's less likely, we accept or reject probabilistically.
Pseudocode
gamma = 4
# NOTE: The Verifier must manage a KV Cache that can be 'rolled back'
kv_state = verifier.prefill(inputs)
# 1. Draft Phase (Sequential)
draft_tokens = []
for _ in range(gamma):
# The drafter runs autoregressively
token = drafter.generate_one(kv_state + draft_tokens)
draft_tokens.append(token)
# 2. Verification Phase (Parallel)
# The verifier processes the original input + all drafts at once
# Returns logits for positions: [last_input, d1, d2, d3, ...]
verifier_logits = verifier.forward(kv_state + draft_tokens)
accepted_tokens = []
for i, draft_token in enumerate(draft_tokens):
# Get probabilities for the specific token 'draft_token'
p_ver = prob(verifier_logits[i], draft_token)
p_draft = prob(drafter_logits[i], draft_token)
# Rejection Sampling Formula
# Accept if Verifier is confident, or probabilistically otherwise
if np.random.random() < (p_ver / p_draft):
accepted_tokens.append(draft_token)
else:
# Rejection! Sample a correction from the residual distribution
# (p_ver - p_draft) re-normalized
correct_token = sample_correction(verifier_logits[i], p_draft)
accepted_tokens.append(correct_token)
break # Stop accepting drafts
else:
# Bonus token: If all drafts accepted, we get one extra token "for free"
extra_token = sample(verifier_logits[-1])
accepted_tokens.append(extra_token)
# 3. Rollback / Pruning
# The verifier.forward() call above computed KV entries for ALL draft tokens.
# If we rejected early, the cache now contains invalid future states.
# We must truncate the Verifier's KV Cache to keep only the valid prefix.
verifier.rollback(keep_tokens=len(accepted_tokens))
# Append valid tokens to state
kv_state.append(accepted_tokens)
The Added Latency Paradox
An interesting byproduct of this method is that each individual step is becoming slower. We have to first run multiple steps of the Drafter, then decode multiple tokens in parallel using the Verifier.
The added latency from the Drafter can be managed by keeping the Drafter small. The added tokens to the Verifier do not add a lot of latency because we are so much memory bound in Decode anyway.
We reduce latency not by making each step faster, steps are actually longer. We reduce latency by increasing the total amount of tokens generated at every step. If the Drafter is good enough, it can significantly reduce overall latency.
In production, we need to monitor the impact on step time of the technique as well as the average amount of tokens accepted per step. These two data points will inform how we should set \(\gamma\).
- If the average accepted tokens count is
3, but \(\gamma=10\). We clearly should reduce \(\gamma\) to around4. - On the other hand, if we accept nearly all tokens, we should consider increasing \(\gamma\).
Lenience
So far, Speculative Decoding is a quality neutral technique. However, the authors of the paper introduced a lesser known component in the appendix: lenience.
It simply changes the acceptance formula to
\[\text{is_accepted} = \text{random_uniform}(0, 1) < \frac{P_{\text{verifier}}(x)}{P_{\text{drafter}}(x) * lenience}\]
It is another knob we can turn to increase the amount of predicted tokens artificially. The lower the value, the more tokens we accept. However, this means that we are now accepting tokens we normally would not have. It is mostly fine because we still reject tokens that make no sense at all (depending on the lenience value.) Lenience should be empirically tested before applying. A nice property is that it can simply be set dynamically during serving, so during traffic spikes, the value could be lowered, thus reducing latency.