Data Parallelism
Data Parallelism (specifically Distributed Data Parallel or DDP) is the most common scaling strategy. It is simple: We shard the data by splitting it over multiple chips, but we replicate the model.
Let's explore this einsum:
out = torch.einsum('bd,df->bf', activations, weights)
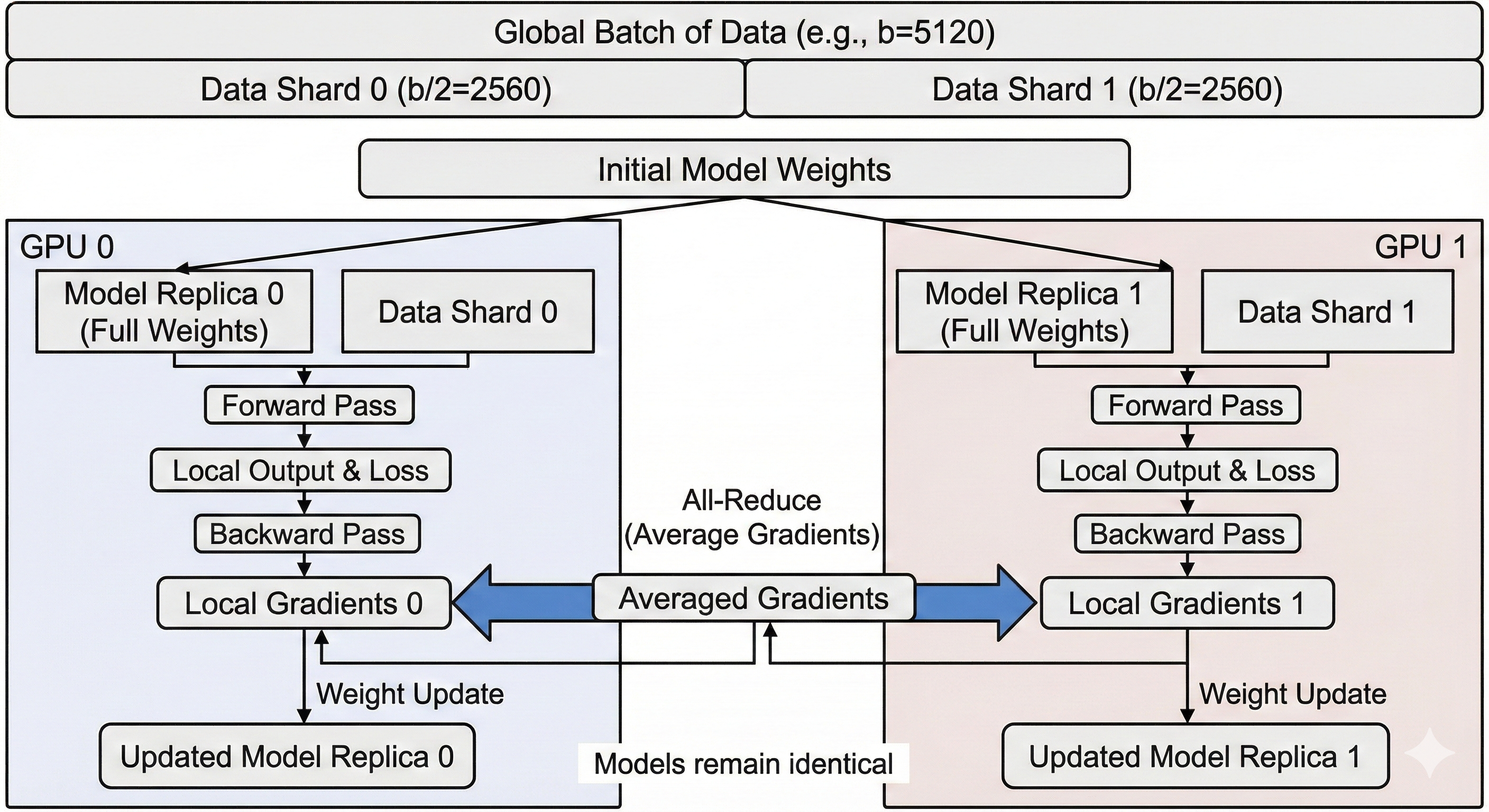
Let's set b to 5120, d to 2048 and f to 1024. If we have 2 GPUs, each GPU will see one half of b (2560 vectors of size d each) and have a full replica of the weights.
In a forward pass, this means we never have to synchronize and we just run half our batch on a chip, and another half on the other chip. During the backward pass, we have to average the gradients from each GPU (using an all-reduce) to update our weights with the same value and maintain them replicated.
The Limit: Memory Redundancy
The main limitation of standard Data Parallelism is Memory. Because every GPU must hold a full copy of the weights, the gradients, and the optimizer states, the maximum model size is limited to what fits on a single GPU.
If your model is 80GB and your GPU has 40GB of VRAM, you cannot use standard Data Parallelism, even if you have 100 GPUs.
| Feature | Impact | Why? |
|---|---|---|
| Implementation | ✅ Easy | Supported natively (e.g., PyTorch DDP). It requires almost no code changes; you just wrap the model and the framework handles the gradient synchronization. |
| Throughput | ✅ High | Ideally provides linear scaling. If you double the chips, you process double the data per second (until network limits are reached). |
| Memory | ❌ Low | The major bottleneck. Every chip must store a full replica of the parameters, optimizer states, and gradients. You cannot train a model larger than what fits on a single chip. |
| Communication | ⚠️ Medium | Requires an All-Reduce of gradients after every backward pass. While bandwidth-heavy, it is often overlapped with computation. However, it is sensitive to "stragglers" (if one GPU is slow, all GPUs wait). |
| Batch Size | ⚠️ Rigid | To scale up, you must increase the Global Batch Size. If you keep Global Batch Size constant while adding GPUs, the per-GPU batch size shrinks, leading to low Arithmetic Intensity and poor hardware utilization. |
Code
We inherit from our Unsharded Single Device implementation. The forward pass remains exactly the same (local computation). We only need to override backward to add the synchronization step.
- Performance Note: This implementation is "naive" because it waits for the backward pass to finish before syncing. Production systems (like PyTorch DDP) use Gradient Bucketing: they trigger the
all_reducefor LayerNimmediately while LayerN-1is still computing gradients, hiding the communication latency.
class DataParallel(SingleDevice):
def backward(self, grads: npt.ArrayLike) -> dict[str, npt.ArrayLike]:
# 1. Compute local gradients on this device's slice of data
# Returns: {'layer_0/weights': local_grad_0, ...}
grads_dict = super().backward(grads)
w0_grads = grads_dict['layer_0/weights']
w1_grads = grads_dict['layer_1/weights']
# 2. Synchronize Gradients across all devices
# We average them so the update step behaves as if we processed the full batch.
synced_w0_grads = self.all_reduce(w0_grads, op='avg')
synced_w1_grads = self.all_reduce(w1_grads, op='avg')
return {
'layer_0/weights': synced_w0_grads,
'layer_1/weights': synced_w1_grads
}