Mixture of Experts (MoE)
Mixture of Experts (MoE henceforth) is arguably the most impactful modeling innovation since the attention mechanism. It allows increasing the number of parameters in the MLP block without proportionally increasing the number of flops.
Instead of a single large matrix multiplication, we split our weights into \(e\) experts. Each token gets assigned to \(k\) experts based on a router (which is learnt.) We train \(e\) experts but only activate \(k\) experts per token during inference.
In the next sub-chapters, we will implement a simple kernel for single device MoE, then we will discuss different sharding strategies, and discuss problems with inefficient load balancing (expert imbalance.) For now, let's implement a NumPy version of MoE.
Basic Implementation
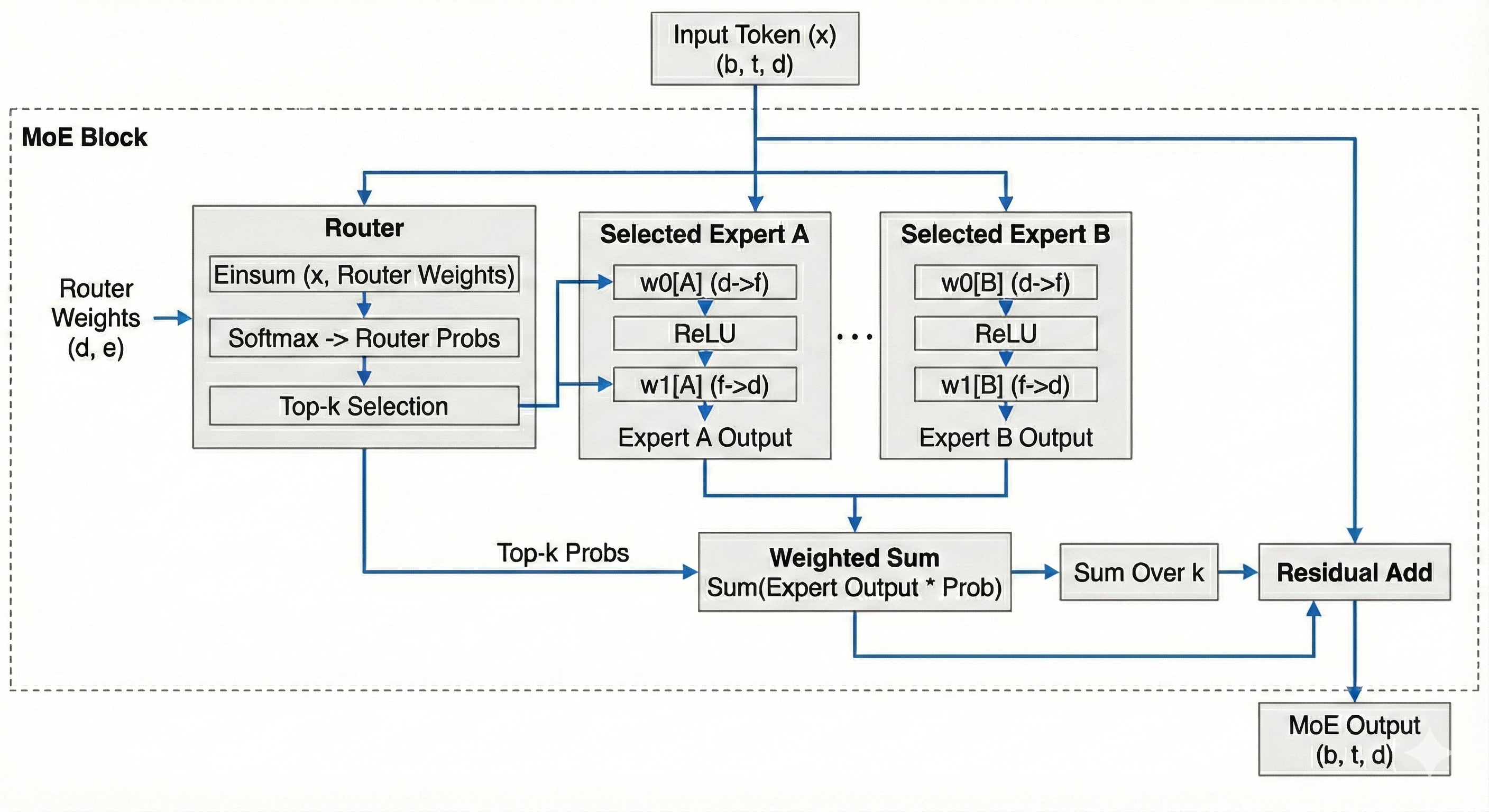
import numpy as np
def softmax(x):
e_x = np.exp(x - np.max(x, axis=-1, keepdims=True))
return e_x / np.sum(e_x, axis=-1, keepdims=True)
def moe(x, router_weights, w0, w1, k: int = 2):
"""
x: (b, t, d)
router_weights: (d, e)
w0: (e, d, f)
w1: (e, f, d)
"""
num_experts = w0.shape[0]
b, t = x.shape[:2]
# (b, t, d) -> (bt, d)
x = x.reshape(-1, x.shape[-1])
expert_choices = np.einsum('Bd,de->Be', x, router_weights)
# (bt, e)
router_probs = softmax(expert_choices)
# Indices of the top k experts
# (bt, k)
top_k_indices = expert_choices.argsort(axis=-1)[..., -k:]
# Probabilities corresponding to those experts
# (bt, k)
top_k_probs = np.take_along_axis(router_probs, top_k_indices, axis=-1)
# Normalize
top_k_probs /= top_k_probs.sum(axis=1)
# Assign tokens to experts
tokens_to_expert = [[] for _ in range(num_experts)]
# Store the mapping to reconstruct order later: (expert_id, original_token_idx, k_rank)
reorder_map = [[] for _ in range(num_experts)]
for token_idx, expert_ids in enumerate(top_k_indices):
for k_rank, expert_id in enumerate(expert_ids):
tokens_to_expert[expert_id].append(x[token_idx][None, ...])
reorder_map[expert_id].append((token_idx, k_rank))
# Placeholder for the final combined output
# (bt, k, d)
expert_outputs = np.zeros((x.shape[0], k, d))
# Apply dot products to each expert
for expert_idx in range(num_experts):
if not tokens_to_expert[expert_idx]:
continue
tokens = np.concatenate(tokens_to_expert[expert_idx])
# w0
y = np.einsum('Bd,df->Bf', tokens, w0[expert_idx])
# relu
y = np.maximum(y, 0)
# linear
y = np.einsum('Bf,fd->Bd', y, w1[expert_idx])
for i, (token_idx, k_rank) in enumerate(reorder_map[expert_idx]):
expert_outputs[token_idx, k_rank] = y[i]
# Multiply expert output by router probability
# expert_outputs: (bt, k, d)
# top_k_probs: (bt, k) -> broadcast to (bt, k, 1)
weighted_out = expert_outputs * top_k_probs[:, :, None]
# Reduce over k. Different papers use different methods
# (bt, d)
out = weighted_out.sum(axis=1)
# (b, t, d)
out = out.reshape(b, t, -1)
# Residual
return out + x.reshape(b, t, -1)