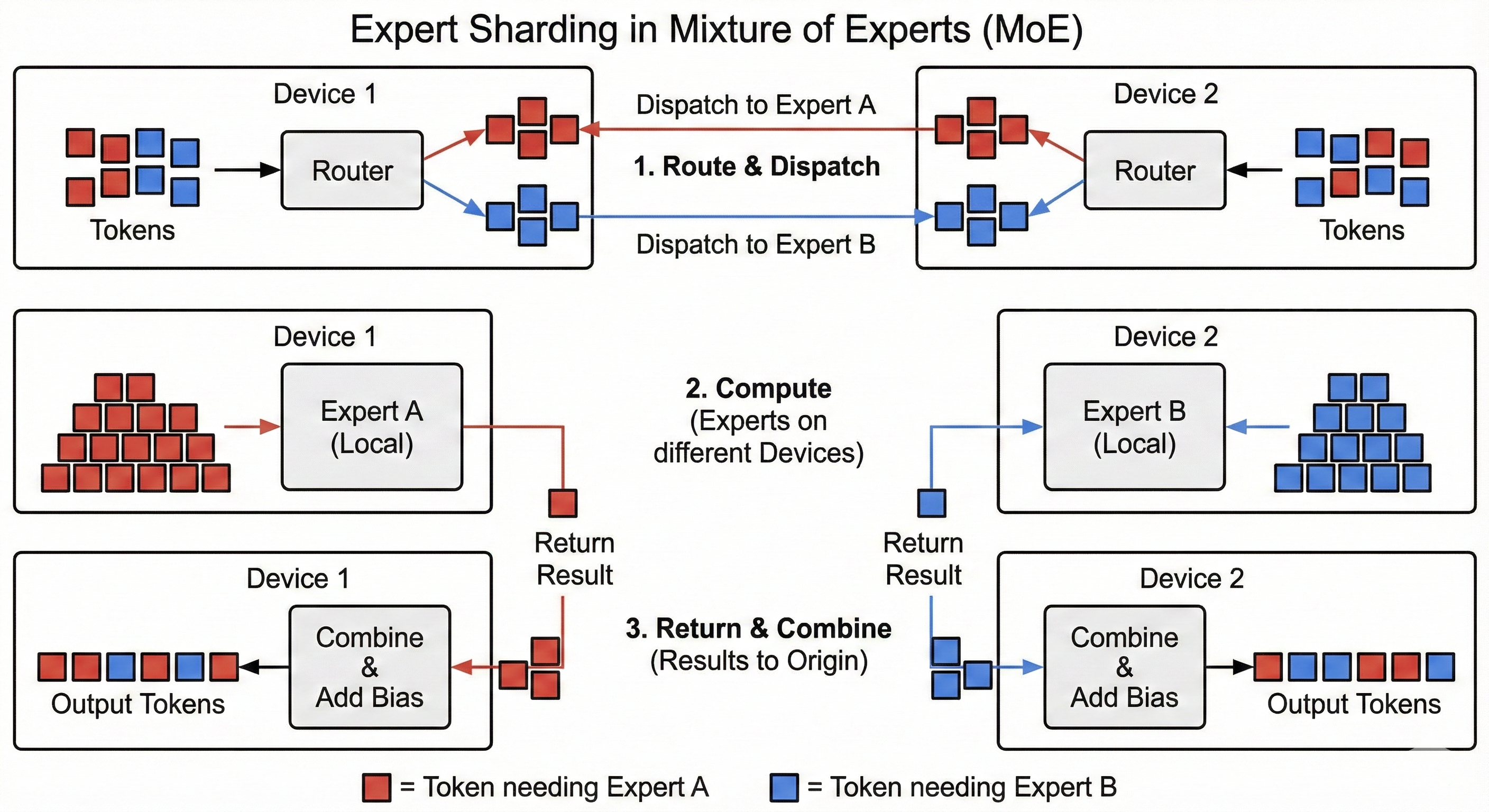
Expert Sharding
MoE opens the door to a new sharding strategy: Expert Sharding. We assign experts to different devices, after we compute the expert choices, we send the tokens to the correct devices where we perform the computations. We then send them back to where they came from.
It is quite different to other sharding strategies because each device will see a different set of tokens and will compute a different amount of tokens.
The only difference with the basic single device implementation is that instead of appending to the local list, we send the tokens to the device who hold the correct experts. The difficulty is that the amount we send to each device is dynamic. Typically, we will need to communicate to each other device in the mesh how many tokens we are sending them. This means we need to All-To-All some metadata about how many tokens were sent from each device concurrently to the tokens we are sending.
Let's rewrite the code using the same Pseudo API using the logic you would find in an MoE kernel but with simplified APIs.
...
def forward(self, x, router_weights, w0, w1, k: int = 2):
"""
x: (b_per_device, t, d)
router_weights: (d, e_total)
w0: (e_per_device, d, f)
w1: (e_per_device, f, d)
"""
num_experts_total = router_weights.shape[1]
num_experts_per_device = w0.shape[0]
# -- SAME AS SINGLE DEVICE --
b, t, d = x.shape
x = x.reshape(-1, x.shape[-1])
expert_choices = np.einsum('Bd,de->Be', x, router_weights)
router_probs = softmax(expert_choices)
top_k_indices = expert_choices.argsort(axis=-1)[..., -k:]
top_k_probs = np.take_along_axis(router_probs, top_k_indices, axis=-1)
top_k_probs /= top_k_probs.sum(axis=1)
# ---------------------------
# Allocate a buffer for the other chips to write to
# We allocate for the worst case scenario where each token
# goes to each expert on the current device
buffer_shape = (num_experts_per_device, self.num_devices() * x.shape[0], x.shape[-1])
# (e_per_device, bt_global, d)
target_buffer = np.zeros(buffer_shape, dtype=np.float16)
# (num_devices, e_per_device)
token_origin = np.zeros((self.num_devices(), num_experts_per_device))
futures = []
# Synchronize all chips to ensure they are at the same point
# so it's safe to write to the buffer (address is allocated everywhere.)
self.barrier()
# How many tokens we are sending to each expert
sending_amount = np.zeros((self.num_devices(), num_experts_per_device))
# Send the tokens to the other devices
# At the same time, collect the metadata to send to all other devices
for token_idx, expert_ids in enumerate(top_k_indices):
for k_rank, expert_id in enumerate(expert_ids):
# Device that owns the expert
target_device = expert_id // num_experts_per_device
# Local expert idx
target_expert_id = expert_id % num_experts_per_device
# Where to send the token such that it has a unique destination
# into the target buffer.
# This ensures there are no collisions in between devices.
global_token_id = self.my_id() * b * t + sending_amount[target_device, target_expert_id]
# We write x[token_idx] into
# target_buffer[target_expert_id, global_token_id, ...]
# on device target_device.
future = self.send_async(src=x[token_idx][None, ...],
dst=target_buffer[target_expert_id, global_token_id, ...],
target_device_id=target_device)
futures.append(future)
sending_amount[target_device, target_expert_id] += 1
# Communicate to all chips how many tokens we sent them for each expert they hold
for target_idx in range(self.num_devices()):
future = self.send_async(
src=sending_amount[target_idx, :],
dst=token_origin[self.my_id(), :],
target_device_id=target_idx
)
futures.append(future)
# Wait until all communications are over
for future in futures:
future.wait()
# At this point we have collected all the tokens we need into target_buffer.
# We also know how many tokens were sent by each device.
# Most of the buffer is padding, let's extract the tokens next to each other
# to leverage tensor cores.
# (e_per_device, bt_global, d)
ordered_buffer = np.zeros_like(target_buffer)
current_offset_per_expert = np.zeros((num_experts_per_device,))
for orig_idx in range(self.num_devices()):
orig_start_idx = orig_idx * b * t
for local_expert_idx in range(num_experts_per_device):
# How many tokens came from device orig_idx for expert local_expert_idx
count = token_origin[orig_idx, local_expert_idx]
# Slice target_buffer
to_copy = target_buffer[local_expert_idx, orig_start_idx:orig_start_idx+count]
# Where is the current offset
offset = current_offset_per_expert[local_expert_idx]
# Copy at the offset
ordered_buffer[local_expert_idx, offset:offset+count] = to_copy
# Update the offset
current_offset_per_expert[local_expert_idx] += count
# Placeholder for the final combined output
# (e_per_device, bt_global, d)
expert_outputs = np.zeros((num_experts_per_device, b*t*self.num_devices(), d))
# Apply dot products to each expert
for expert_idx in range(num_experts_per_device):
# How many tokens for the given expert
tokens_for_expert = current_offset_per_expert[expert_idx]
# Slice the tokens so we don't process padding
tokens = ordered_buffer[expert_idx, :tokens_for_expert]
# w0
y = np.einsum('Bd,df->Bf', tokens, w0[expert_idx])
# relu
y = np.maximum(y, 0)
# linear
y = np.einsum('Bf,fd->Bd', y, w1[expert_idx])
expert_outputs[expert_idx, :tokens_for_expert] = y
# Write back the output
# (e_total, bt_local, d)
collected_outputs = np.zeros((num_experts_total, b*t, d))
futures = []
self.barrier()
for local_expert_idx in range(num_experts_per_device):
global_expert_idx = self.my_id() * num_experts_per_device + local_expert_idx
current_offset = 0
for orig_idx in range(self.num_devices()):
count = token_origin[orig_idx, local_expert_idx]
future = self.send_async(
src=expert_outputs[local_expert_idx, current_offset:current_offset+count],
dst=collected_outputs[global_expert_idx],
target_device_id=orig_idx
)
futures.append(future)
current_offset += count
for future in futures:
future.wait()
# We now have our outputs, but we need to reorder as (bt, k, d)
expert_outputs = np.zeros((b*t, k, d))
expert_offsets = np.zeros((num_experts_total,))
for token_idx in range(b*t):
for top_k in range(k):
expert_idx = top_k_indices[token_idx, top_k]
offset = expert_offsets[expert_idx]
expert_outputs[token_idx, top_k] = collected_outputs[expert_idx, offset]
expert_offsets[expert_idx] += 1
# -- SAME AS SINGLE DEVICE --
weighted_out = expert_outputs * top_k_probs[:, :, None]
out = weighted_out.sum(axis=1)
out = out.reshape(b, t, -1)
return out + x.reshape(b, t, -1)
Other Ways to Shard
We can shard MoE using different approaches such as Megatron sharding. We can also use hybrid approach, like sharding the experts 8 ways and model 4 ways. This can be useful when we have more devices than experts, forcing us to shard other dimensions.