Tensor Parallelism (TP)
Tensor Parallelism shards the model's parameters and synchronizes the activations using collective operations. It allows saving on memory per chip while also lowering latency by splitting computations across multiple devices.
FSDP gathers the specific layer's parameters just in time for compute and discards them immediately after. The distinction is FSDP shards state (weights/optimizer), whereas TP shards computation (matrix multiplication).
There are multiple ways to implement Tensor Parallelism. The best method will depend on your model's architecture and dimensions. A common example for LLMs is Megatron Sharding.
How to think about TP?
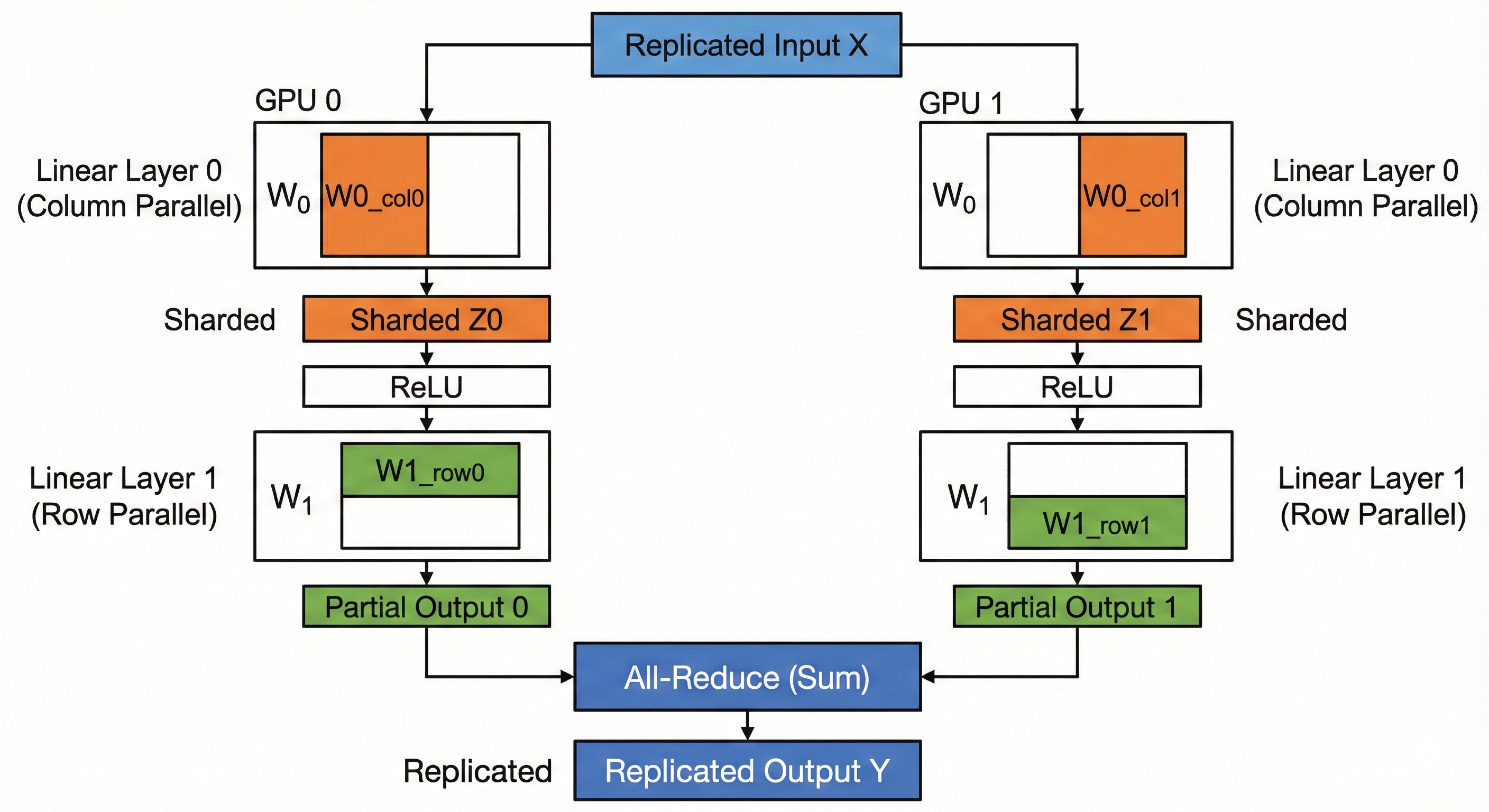
The golden rule of TP is: Internal bandwidth is fast; Inter-chip bandwidth is slow. We want to structure our matrix multiplications so that we don't need to talk to other chips between every operation.
We achieve this by pairing two specific types of sharding:
- Column Parallelism (Layer 0 in the code example):
- Split the weight matrix \(W_0\) along the columns (Hidden Dimension).
- Input \(X\) is replicated.
- Each chip computes a chunk of the output vectors.
- Result: The output activation \(Z\) is sharded along the hidden dimension. No communication needed.
- Row Parallelism (Layer 1 in the code example):
- Split the weight matrix \(W_1\) along the rows (Hidden Dimension).
- Input \(Z\) is already sharded along the hidden dimension (thanks to Layer 0).
- Each chip computes a dot product using its local shard.
- Result: Each chip has a partial sum of the final output.
- Communication: We perform one single All-Reduce to sum the partial results.
By combining these, we perform an entire MLP block (Linear->ReLU->Linear) with only one synchronization step at the very end.
Code
Let's implement our initial unsharded model with Tensor Parallelism.
We implement the standard Megatron-style TP.
- World Size (N): Number of devices.
- \(W_0\): Shape \((Model, Hidden // N)\).
- \(W_1\): Shape \((Hidden // N, Model)\).
We assume the input x is replicated (identical copies on all devices).
class TensorParallel(ShardedEngine):
def __init__(self, model_dim: int, hidden_dim: int):
# We divide the Hidden dimension by the number of devices
self.local_hidden_dim = hidden_dim // self.num_devices
# W0: Column Parallel (Split output dim)
self.w0 = np.zeros((model_dim, self.local_hidden_dim), dtype=np.float32)
# W1: Row Parallel (Split input dim)
self.w1 = np.zeros((self.local_hidden_dim, model_dim), dtype=np.float32)
self.activations = []
def load_checkpoint(self, params: dict[str, npt.ArrayLike]) -> None:
# Determine which slice of the Hidden dimension this device owns
start = self.device_id * self.local_hidden_dim
end = start + self.local_hidden_dim
# Load W0: Slice columns
self.w0[...] = params['layer_0/weights'][:, start:end]
# Load W1: Slice rows
self.w1[...] = params['layer_1/weights'][start:end, :]
def forward(self, x: npt.ArrayLike) -> npt.ArrayLike:
# x is Replicated: Shape (Batch, Model)
self.activations.append(x)
# 1. Column Parallel Linear
# (Batch, Model) @ (Model, Hidden/N) -> (Batch, Hidden/N)
# Each device computes a valid slice of the output vector.
z = np.einsum('bd,df->bf', x, self.w0)
# NO COMMUNICATION NEEDED HERE
# The output 'z' is inherently sharded along the Hidden axis.
# 2. Activation
# ReLU works element-wise, so we can apply it to the shards independently.
self.activations.append(z)
z = relu(z)
# 3. Row Parallel Linear
# (Batch, Hidden/N) @ (Hidden/N, Model) -> (Batch, Model)
# We contract the sharded axis (Hidden).
# This results in a PARTIAL SUM of the output.
partial_out = np.einsum('bf,fd->bd', z, self.w1)
# 4. All-Reduce
# Sum the partial results from all devices to get the final full output.
out = self.all_reduce(partial_out, op='sum')
return out
def backward(self, grads: npt.ArrayLike) -> dict[str, npt.ArrayLike]:
"""
grads: Incoming gradient dL/d(Output) of shape (Batch, Model)
"""
# --- Backprop Layer 1 (Row Parallel) ---
# The forward pass ended with an All-Reduce (Sum).
# The backward pass of All-Reduce(Sum) is Identity (copy gradients to all).
# So 'grads' is already correct and replicated.
z = self.activations.pop() # Shape (Batch, Hidden/N)
h_relu = relu(z)
# dL/dW1 = h.T @ grads
# (Hidden/N, Batch) @ (Batch, Model) -> (Hidden/N, Model)
# Result matches local W1 shape. No comms needed.
w1_grad = np.einsum('bf,bd->fd', h_relu, grads)
# dL/dz = grads @ W1.T
# (Batch, Model) @ (Model, Hidden/N) -> (Batch, Hidden/N)
# Result is sharded (matches z). No comms needed.
dz = np.einsum('bd,fd->bf', grads, self.w1)
# --- Backprop Layer 0 (Column Parallel) ---
dz = dz * (z > 0) # Backprop ReLU
x_input = self.activations.pop() # Shape (Batch, Model)
# dL/dW0 = x.T @ dz
# (Model, Batch) @ (Batch, Hidden/N) -> (Model, Hidden/N)
# Result matches local W0 shape. No comms needed.
w0_grad = np.einsum('bd,bf->df', x_input, dz)
# dL/dx = dz @ W0.T
# (Batch, Hidden/N) @ (Hidden/N, Model) -> (Batch, Model)
# We are contracting the sharded axis (Hidden/N).
# This produces a PARTIAL SUM of dx.
dx_partial = np.einsum('bf,df->bd', dz, self.w0)
# To get the true dL/dx, we would need to All-Reduce here.
# However, for weight updates, we strictly return the weight gradients below.
return {'layer_0/weights': w0_grad, 'layer_1/weights': w1_grad}